Introduction¶
Theory and Data¶
The website missingprofits.world computes what each country loses to tax heavens. But how do we reform the tax system so that profits are taxed? What effects would a wealth tax have on inequality? How much revenue could it generate? We need micro theory to understand incentive effects created by taxes. We also need data. Economists like Emmanuel Saez and Gabriel Zucman study these questions with data and theory.

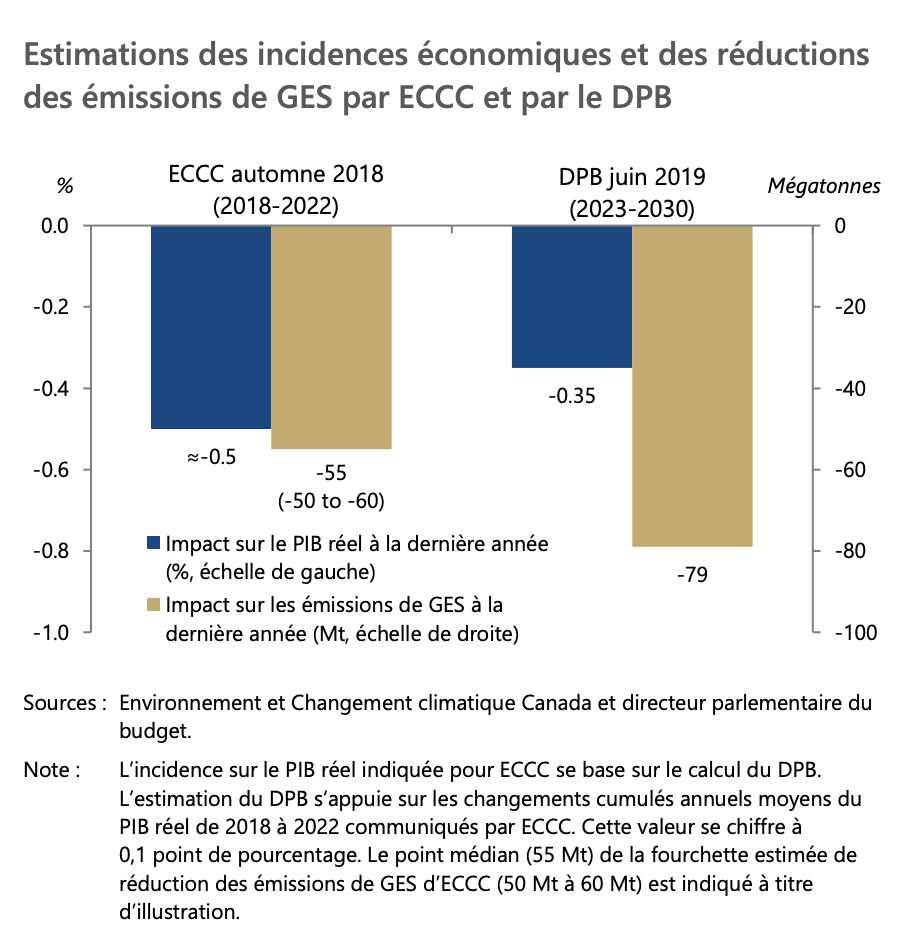
A carbon tax could be effective to reduce emissions. But what are the effects of such taxes on the economy? In 2019, the Parlementary Budget Office of Canada wrote a report which uses an economic model to compute these effects. The model combines data and theory.
How should we set up the market for advertising on the internet? What is the price of information? How should we price rankings in search engines? Hal Varian is the chief economist at Google. He is also the author of a well-known micro theory book. In his everyday work, he combines theory and data to help companies in the new economy. See this interview with him.

Data is everywhere. Theory helps make sense of it:
To understand behavior
To quantify effects of policies and assess them
Pricing and optimization in firms
See also
This article from Judea Pearl, a pioneer in AI, warns of the dangers of using data without theory (in his words, cause to effect mechanisms).
Mathematical Toolbox¶
Math is essential to understand behavior, measure effects of changes in the environment (e.g. prices and taxes). Here is a explainer on a number of key tools we will be using.
Marginal Analysis and Approximations¶
How do we describe a function \(f(X)\)?
Functions can be complicated, can be approximated by linear functions for small perturbations… Here is a function in Python, a langage we will use:
def f(x):
return x**2
def g(x):
return 1/x
Locally, we can do an approximation of a smooth function for \(X\) close to \(X_0\):
\[f(X) \simeq f(X_0) + \alpha (X-X_0)\]
Here is an approximation, for a given \(\alpha\):
def fa(x,x0,alpha):
return f(x0) + alpha * (x - x0)
To find the best \(\alpha\), we have that for \(X\) close to \(X_0\)
In python,
x = 2
x0 = 1
alpha = (f(x) - f(x0))/(x-x0)
But this is cheating! If we know the value of the function, we do not need an approximation. Note that \(\alpha\) looks like a derivative if the change is small.
Recall the first derivative of a function,
We can use a very small \(\epsilon\) and approximate this using:
def fp(x0):
eps = 1e-6
return (f(x0+eps) - f(x0))/eps
The approximation becomes:
In Python we can write:
def fa(x,x0):
return f(x0) + fp(x0)*(x-x0)
If we want to predict the change in a function for a small change in its argument, the derivative is a great way to do it… There are recipes for derivatives such that we do not need to compute them numerically using the function above.
Important
An approximation is less precise for \(\epsilon = X - X_0\) large.
Derivatives¶
Here is a set of recipes…
With constants
\(f(X) = b + aX\): \(f'(X) = a\)
\(f(X) = \log x\): \(f'(X) = \frac{1}{X}\)
\(f(X) = e^{aX}\): \(f'(X) = ae^{aX}\)
\(f(X) = X^a\): \(f'(X) = a X^{a-1}\)
With functions
Product rule: \(f(X) = a(X)b(X)\), \(f'(X) = a'(X)b(X) + a(X)b'(X)\)
Quotient rule: \(f(X) = \frac{a(X)}{b(X)}\), \(f'(X) = \frac{a'(X)b(X) - a(X)b'(X)}{b(X)^2}\)
Chain rule: \(f(X) = a(b(X))\), \(f'(X) = a'(b(X))b'(X)\)
Addition (substraction) rule: \(f(X) = a(X) + b(X)\), \(f'(X) = a'(X) + b'(X)\).
Todo
Exercise A: Find the first derivative of : \(f(X)=\sqrt{X},\frac{X}{1+X},\frac{1}{2}X^2 + 2X-10,(1+\frac{X}{2})^2\).
Todo
Exercise B: Compute a first-order approximation of \(f(X)=\sqrt{X}\) around \(X_0\).
Higher Order Approximations
We can compute higher-order derivatives. The second derivative is the derivative of the first derivative, etc. If these higher-order derivatives are not zero, we can improve the approximation of the function for small perturbations. Linear approximations will be bad for curves, etc.
These are Taylor approximations. We then use higher-order derivatives:
We denote \(f'(X), f''(X)\) or \(\frac{d f}{d X},\frac{d}{d X}(\frac{d f}{d X}) = \frac{d^2 f}{d X^2}\) the second derivative of a function. In this course, you will not need to go above second derivatives.
Concavity and Convexity of Functions
A function is concave if for all (pair of) points, \((X_1,X_2)\) and all \(0<\lambda<1\):
and convex if false. We say strictly concave (or convex) if these inequalities are strict.
Note
In simpler terms, if for all pair of points, the line connecting them is below the function, the function is concave, and if above the function, the function is convex.
The second derivative is useful for concavity and convexity. There is a simpler definition for our purposes in this class. A function is strictly concave if the second derivative is negative for all points (\(f''(X)<0,\quad \forall X\)), and strictly convex if positive for all points ((\(f''(X)>0,\quad \forall X\)). Examples of concave functions include power functions, \(f(X)=X^{\alpha}\) for \(\alpha<1\) and \(f(X)=\log(X)\). Examples of convex function are power functions with \(\alpha>1\) and \(f(X)=\exp(X)\).
Approximation and Optimum
Consider the first order approximation
We have that if:
\(f'(X_0)>0\), a small change \(\Delta X>0\) increases \(f\)
\(f'(X_0) <0\) a small change \(\Delta X <0\) increases \(f\)
\(f'(X_0) =0\), then \(X_0\) is the solution to \(\max_X f(X)\).
This last first order condition (FOC) is necessary for an optimum. We need the first derivative to be zero at the optimum.
The FOC is not sufficient. We also need a second condition, i.e. that the second derivative is negative. Here we skip the details, but this avoids inflection points, where the FOC is satisfied but where we do not have a maximum or a minimum.
Todo
Exercise C: Find the maximum for the function \(f(X) = X(10-X)\).
Partial Derivatives¶
Consider the function \(f(X,Y)\). The partial derivative changes one variable, keeping the others fixed: \(f'_X(X,Y) = \frac{\partial f(X,Y)}{\partial X}\).
Note
A partial derivative does not represent an additional difficulty. We can rewrite the case above of a function \(f(X) = aX\) as \(g(X,a) = a X\) and therefore \(g'_X(X,a) = f'(X) = a\). One treats other variables as constants!
Total Differentiation¶
Sometime, it makes sense to look at combinations of \((X,Y)\) that keep the function fixed to some value \(f(X,Y) = \overline{f}\). We can invert the function, \(Y=g(X,\overline{f})\). As an example, consider \(f(X,Y) = \log(X) + \log(Y)\). If we set \(f(X,Y)=10\). Then we can write, \(Y = \exp(10 -\log(X))\). But, we can also use total differentiation to characterize the relationship between \(X\) and \(Y\) for a given value of the function. This trick exploits linear approximations.
We can perturb a function starting at a point and this equation holds
The operator \(d\) denotes a change. If we set \(df(X,Y)=0\), we can rearrange to obtain:
We add \(df=0\) to indicate that it is a derivative, keeping the value of the function fixed.
Todo
Exercise D: Find \(\frac{dY}{dX}\Bigr|_{df=0}\) using total differentiation \(f(X,Y)=\log(XY)\).
Homogeneity of a Function¶
A partial derivative provides information of how a function changes when we change one variable, keeping others fixed. But sometimes we want to understand how a function changes when all its variables change in the same proportion. Just like we want to know whether if we double a recipe for a cake, we get two cakes, or something else. This is called the degree of homogeneity of a function. There are two ways to proceed:
Direct approach: A function is homogeneous of degree \(r\) if for all \(\lambda>0\),
Euler Theorem: If a function is homogeneous of degree \(r\), then:
Todo
Exercise E: Find the degree of homogeneity of the function \(f(X,Y)=X^\alpha Y^\beta\) using both methods.
Maximum and Approximation¶
We need as many first-order conditions as there are variables we maximize over. The necessary conditions are
for a function \(f(X,Y)\). The second order conditions are a bit more complicated and we do not cover it here.
Constrained Maximization¶
A constrained problem takes the form:
The Lagrangian
The method proposed by Lagrange is to solve for the pair \((X,Y)\) using the set of three conditions:
Where \(\lambda\) is a Lagrange multiplier.
If we think backwards, these three equations are the first order conditions to maximizing a Lagragian \(L(X,Y,\lambda)\):
where
The Lagrangian \(L(X,Y,\lambda)\) is a modified objective function which penalizes the constraint added to the unconstrained maximization of the objection function. If \(\lambda = 0\), the first two FOC above are the unconstrained FOC, \(f'_X(X,Y)=0\) and \(f'_Y(X,Y)=0\) which yield the unconstrained optimum. If one of the constraints is binding (if \(\lambda \neq 0\)) will we get a different solution.
Todo
Exercise F: Maximize the function \(f(X,Y) = \log X + \log Y\) under the constraint \(X+Y \le m\) using a Lagrangian.
Note on logs¶
In these notes, we use \(\log\) to denote the logarithm with base \(e=2.718281828459\) and not base 10. So, it is the natural log (\(\ln = \log_e\)). Python also uses this base in the numpy library.
Introduction tp Python¶
This first notebook should help you take your first steps with Python on Google Colab.
![]()