Welfare¶
We can look at a policy using efficiency: does it target the right group, does it have the intended effect and how much does it cost? For example, we could evaluate a policy that increases air quality and leads people to changer their behavior. The economic cost per unit of improvement in air quality may be large. But what can we compare it to? What is the threshold above which the policy does not increase welfare.
While many limit themselves to economic and fiscal impacts, benefits may go beyond what we observe in markets. Air quality is valued by consumers. Poor air quality lead to health problems makes our life more difficult. We want to measure benefits from preferences but these are not directly observable. This is the fundamental problem of welfare analysis.
Three popular approaches are used to measure up welfare impacts of policies (benefits and costs): a utilitarian, hicksian and finally one based on self-reported happiness.

Utilisarism¶
For each consumer \(i\in \{1,\ldots,N\}\), we can construct a utility function \(u_i\) representing preferences over a basket of goods \(B\) (for example \((X,Y)\)). Consider the situation where each citizen has basket : \(B_1\), \(B_2\), …, \(B_N\). According to this approach, we can measure welfare of this group of consumers using
If we use this welfare criterion, a policy \(\mathcal P_0\) is better than an alternative \(\mathcal P_1\) if the sum of utility levels is larger. The function that aggregates utilities of each citizen is linear, as proposed by Bentham, but can also take other forms, for example taking the utility of the consumer who has the lowest one which implements the social justice criterion of Rawls.
This approach is problematic. It assumes that utility levels are comparable across consumers. But we saw that these are ordinal, that the absolute level has no meaning. Recall that \(u_1\) represents preferences of citizen \(1\), but \(f(u_1)\) represents the same preference for any strictly increasing function \(f\). There exist an infinite number of utility functions which represent the same preferences. For example, we could rescale utility as \(2\times u_1\), which could create an advantage for a policy if this policy is favorable to a particular citizen.
The ranking of policies is therefore ambiguous: we can have \(\mathcal P_0\) ranked better if \(w = u_1 + u_2\) while \(\mathcal P_1\) is better if we use \(W = 2u_1 + u_2\).
In the end, welfare should depend on preferences and not on \(u\). But utilities remain useful in some more restricted capacity.
Important
We can for example define a Pareto Improvement, if utility of all consumers is at least equal to their level before a change in policy, but strictly higher for at least one consumer. If no one loses, and some win, this situation is an improvement in a Pareto sense.
Pareto improvements respect the fact that utility is ordinal. This is progress on our quest…
Compensating Variation¶
A promising approach is to quantify welfare in monetary terms using preferences. John Hicks has proposed to use compensating variation. Let’s see how this works.
We first define what a policy is. For the consumer, what is a policy? A policy \(\mathcal P\) affects the budget constraint \(C_i(\mathcal P,I_i)\) of consumer \(i\) (where \(I_i\) is income).
We can use indirect utility as a starting point. The highest level of utility a consumer \(i\) can obtain given his budget constraint is:
\[v_i(\mathcal P,I_i) = \max_{B \in C_i(\mathcal P, I_i)} u_i(B)\]
Example: Two goods \(X\) and \(Y\). Utility is \(u(X,Y) = \log X + \log Y\). A policy \(\mathcal P\): implements a multiplicative tax \(\tau\) on the price of \(Y\). Indirect utility is given by:
So this is the maximum utility that can be reached with a particular policy. If we assume agents optimize, this is the level of utility reached by consumers with this policy.
Denote \(\mathcal P_0\) the status quo and consider implementing a policy \(\mathcal P\). We can define the compensating variation as the amount of money \(\Delta I_{CV}\) such that
\[v(\mathcal P_0,I) = v(\mathcal P,I - \Delta I_{CV})\]
Note
The compensating variation is the amount of money we must take away from the consumer to keep his utility constant at the level found under the status quo.
Note
We use the sign convention \(\Delta I_{CV}>0\) when the policy is beneficial, for example a tax rebate, an increase in transfers, an increase in air quality or health.
Todo
Exercise A: Find the expression of compensating variation for \(u(X,Y) = XY\) and a multiplicative tax \(\tau\) on good \(Y\).
The compensating variation is invariant to monotone transformation of the utility functions, unlike the utilitarism criteria.
Special case¶
Consider preferences for a good \(X\) and cash \(Y\). Preferences are represented by \(u(X,Y) = g(X) + Y\). We call those quasi-linear preferences. Since \(Y\) is cash, we normalize \(p_Y=1\).
The policy in the status quo is \(\mathcal P_0\). The consumer picks the allocation \((X_0, Y_0)\). Now, consider the change \(\mathcal P\). The new optimal choice is \((X_1, Y_1)\).
In this case, the compensating variation is \(\Delta I_{CV}\). It implies a loss in cash \(Y\).
The compensating variation is equal to a change in utility. Because of the linearity of utility in cash, utility is in dollars. Another interesting property is that the MRS, the value of \(X\) is therefore in dollars and given by:
Since \(p_Y=1\) in the case where \(Y\) is cash, \(g'(X)\) represents the willingness to pay (in dollars) for an additional unit of \(X\). It defines the inverse demand function since when the consumer optimizes, we have the FOC, \(p_X = g'(X)\).
Consumer Surplus¶
We want to define the value of being able to consume a level of \(X\) given some price \(p_X\). Consider the case of quasi-linear preferences for the good \(X\) and cash \(Y\), \(u(X,Y) = g(X) + Y\). Let us assume that \(g\) is concave (\(g'(X)\) decreases in \(X\)).
The status quo is a situation where the good \(X\) cannot be purchased \(\mathcal P_0\) and an alternative where \(\mathcal P\) allows to purchase \(X\) at price \(p_X\). The problem is given by
Since \(u(\cdot)\) is increasing in both goods, we can substitute the constraint to obtain \(\max_{X} g(X) + I - p_X X\). The FOC
which allows to find demand \(X^*(p_X)\). Denote \(p_X(X) = g'(X)\), the inverse demand function. A point on this inverse demand reads as the willingness to pay for an additional unit of \(X\).
In the case of a new product, the compensating variation from \(\mathcal P_0\) to \(\mathcal P\) is defined as consumer surplus:
The first term is the area under the inverse demand curve, from zero to the quantity demanded:
It amounts to the sum of willingness to pay for each unit of \(X\). The second term is the cost of purchasing quantity \(X^*\). The surplus is due to the fact that the consumer values each unit that he purchases at price \(p_X\) more than the price he paid \(p_X\).
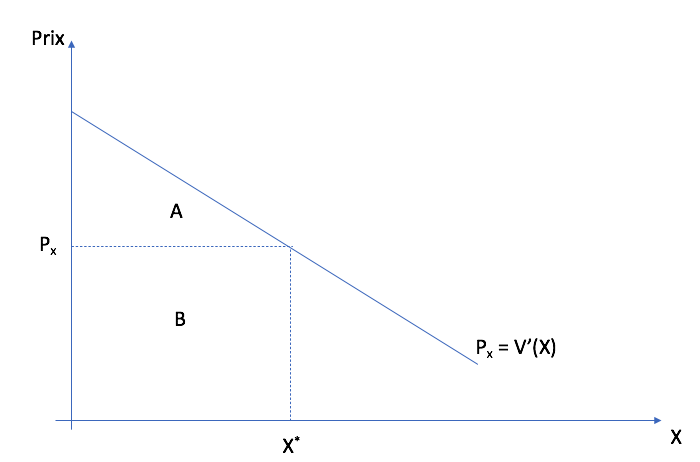
The area A+B is given by \(g(X^*) - g(0)\) while area B is expenditures \(p_{X}X^*\). Therefore consumer surplus is A+B - B = A.¶
Todo
Exercise B: If \(g(X) = 10 X - \frac{1}{2}X^2\), find the expression of consumer surplus.
Welfare and Taxation¶

Taxation impacts the price paid by the consumer. Therefore, it has effects on welfare (since higher prices lower welfare). Compensated income will help quantify the welfare loss from higher prices (or taxes).
Consider eliminating a tax, the price decreases from \(p_X = p+t\) to \(p_X = p\) . We have \(X^*(p) > X^*(p+t)\) (we are not in a Giffen good situation). Income from the tax is \(T= t X^*(p+t)\). When the government collects a tax, we assume that the revenues are distributed lump-sum (an amount for each consumer, not dependent on actions). From a welfare point of view, revenue collected from the government is not lost (implicitly it funds services, etc). Here we recognize its cash value.
In terms of compensating variation, we have
Recognizing the value of tax revenues, the change in welfare from introducing a tax is,
We will obtain that \(-\Delta I_{CV} > T\). As exercise C will show, the consumer is willing to pay an amount which is superior to the revenue generated by the tax. Hence, eliminating the tax is beneficial.
The case of eliminating a tax is similar. The welfare gain associated with eliminating the tax is therefore \(\Delta w = \Delta I_{CV} - T\). Why is \(T\) subtracted? Removing the tax, the government cannot redistribute anymore the proceeds lump-sum. Hence, we have to subtract it from the change in consumer surplus.
Todo
Exercise C: If \(g(X) = 10 X - \frac{1}{2}X^2\), find the welfare loss associated with a new tax \(t\) on good \(X\). Show this loss graphically.
Welfare and Air Quality¶
Generally, consumers have a positive preference for air quality.

There is no market for air quality. With the Clean Air Act (1977), the American government has put in place a number of regulations which reduce pollution and improve air quality.
Consider a policy change from \(\mathcal P_0\): no control and costs, to \(\mathcal P\): pollution controls and costs. The compensating variation should be positive for consumers if they value air quality.
Empirically, how can recover such a preference?
We can aim to find a situation where consumers had to face a trade-off between pollution and income (wealth). For example, the decision to purchase a home may depend on the price of the home but also air quality of the neighborhood. Price and air quality vary inside a city. In a market, prices should be higher if air quality is higher if consumers value air quality.
Using data from real estate transactions, we can determine the value given to air quality. Define \(X\) as air quality, (e.g. air particule concentration) We might want to assume preferences are given by:
With this utility function \(g'(X)\) represents a willingness to pay for air quality. Running a linear regression real estate transaction amounts on \(X\) controlling for other factors, we obtain an estimate of \(g'(X)\).
Chay et Greenstone (2005) obtain a price-particle elasticity between -0.2 and -0.35.

Now, how do we evaluate a policy with this information? The government implements \(X_{GOV}\). The total cost of these measures is \(c X_{GOV}\) where \(c>1\) is the marginal cost, including the welfare loss from raising this amount of revenue to fund these measures.
The policy change is from \((0,0)\) to \((X_{GOV}, - c X_{GOV})\). Consumer surplus is the compensating variation:
This serves as a basis for performing cost-benefit analysis. Once this analysis is done, a follow-up question to ask is: what is the optimal amount of air quality?
Optimal air quality is the level which maximizes
The FOC is
\[g'(X^*) = c\]
We can therefore find out this optimal level once we know these qualities.
Todo
Exercise D: Noise pollution. The price elasticity of house prices to noise pollution is -0.2. The average price of a house is 400 000$. The government considers reducing pollution by 10% near a highway. Engineers estimate the necessary technology will cost 1000$ per house protected (a sound wall). The policy is financed by a tax, which leads to a welfare loss of 43 cents for each dollar that needs to be raised. Would building the sound wall be beneficial in terms of welfare?
This approach is used a lot. It does not require per se knowledge of preference. However, it raises a number of distributive issues if preferences differ across consumers. When the benefits are larger than the cost, but some loose from the policy, we say that the policy is potentially beneficial, implying that compensation may need to take place.
Self-Reported Happiness¶
Why not simply ask consumers of they are happy, or happier after a policy change? On a scale of 1 to 10, are you happy? This avoids making assumptions about preferences, utility. It is an approach that has gained credibility with the 2019 budget in New Zealand. Richard Easterlin is generally credited with making these measures popular. The Easterlin paradox has attracted a lot of attention.
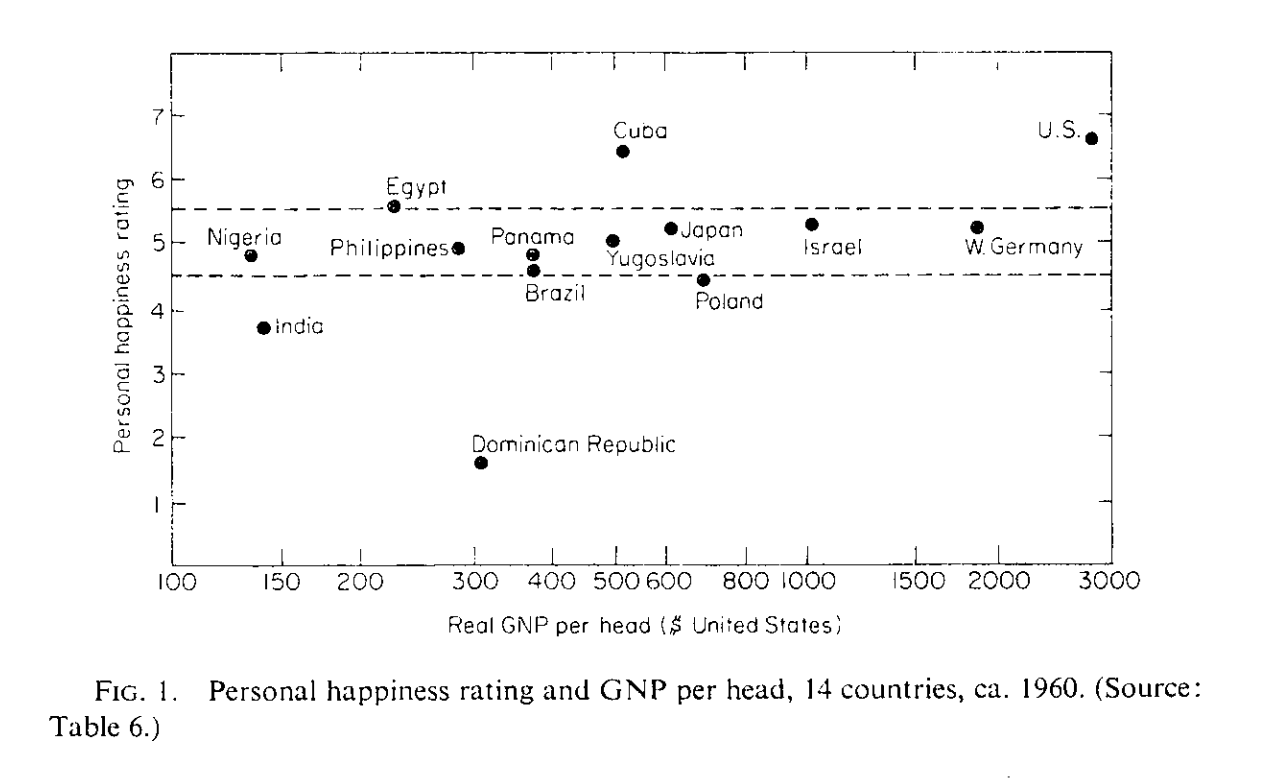
This would suggest that we are not happier with more income: money does not buy happiness. But later, with more data, the expected relationship was shown to hold, in particular for low levels of income.
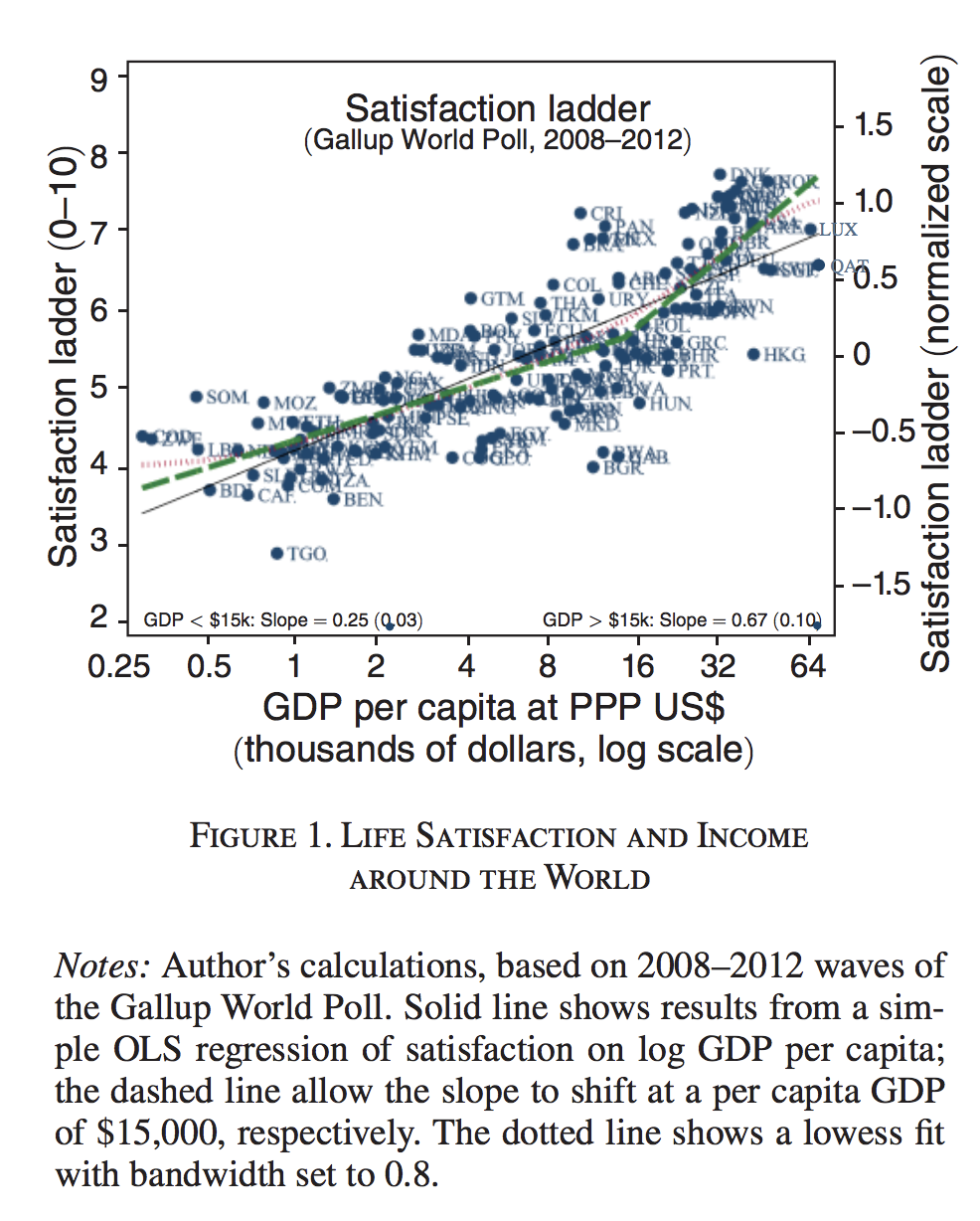
Since happiness is more than income, these measures can be useful. One could use them directly in policy evaluation:
Advantages: direct method, model free.
Disadvantages: We can measure welfare in different ways and people have different ways of answering. Various psychological and framing effects possible.
Few studies use them. But there is a lot of interest, for good reasons.
Microeconomics in Action¶
Here is a podcast with Justin Leroux, professor at HEC Montreal, where we talk about welfare analysis in economics: